示例¶
本节提供 torch-sla 的实用示例。
快速导航
- 可视化:
spy()稀疏模式分析 - I/O 操作: Matrix Market 和 SafeTensors 格式支持
- 线性求解: 直接法和迭代法求解器,支持梯度
- 矩阵分解: SVD、特征值、LU 分解
- 高级应用: 非线性求解、分布式计算
可视化¶
稀疏模式图 (Spy Plot)¶
使用 .spy() 方法可视化稀疏矩阵的非零元素分布。
代码:
import torch
from torch_sla import SparseTensor
# 创建 2D Poisson 矩阵(5点模板)
n = 50
val, row, col = [], [], []
for i in range(n):
for j in range(n):
idx = i * n + j
val.append(4.0); row.append(idx); col.append(idx)
if j > 0: val.append(-1.0); row.append(idx); col.append(idx-1)
if j < n-1: val.append(-1.0); row.append(idx); col.append(idx+1)
if i > 0: val.append(-1.0); row.append(idx); col.append(idx-n)
if i < n-1: val.append(-1.0); row.append(idx); col.append(idx+n)
A = SparseTensor(torch.tensor(val), torch.tensor(row), torch.tensor(col), (n*n, n*n))
# 可视化稀疏模式
A.spy(title="2D Poisson (5点模板)")
输出示例:
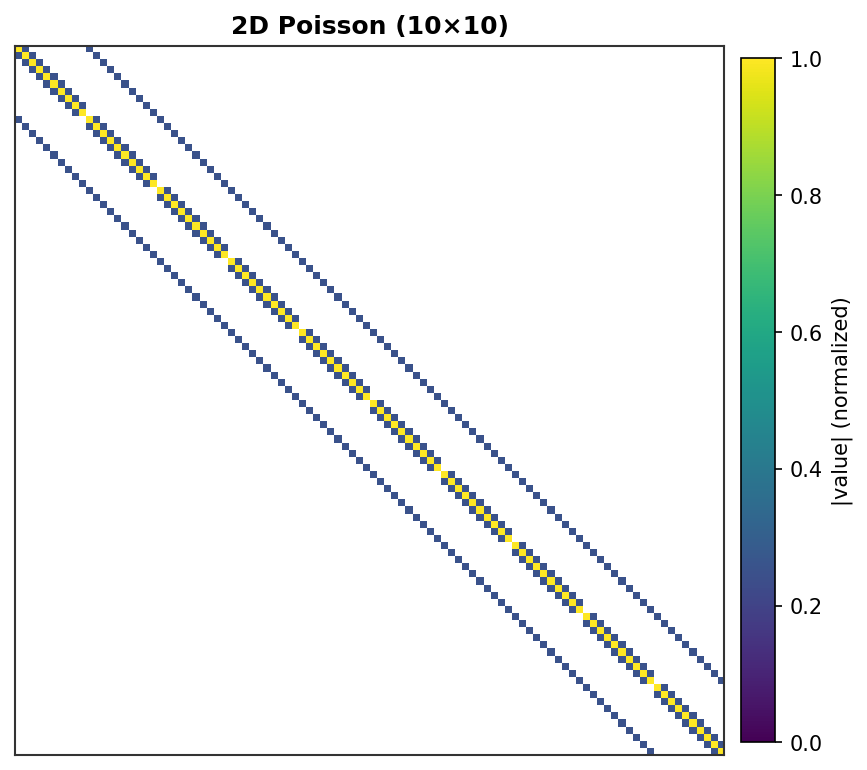
2D Poisson (10×10) - 100 DOF,带网格线的5点模板¶ |
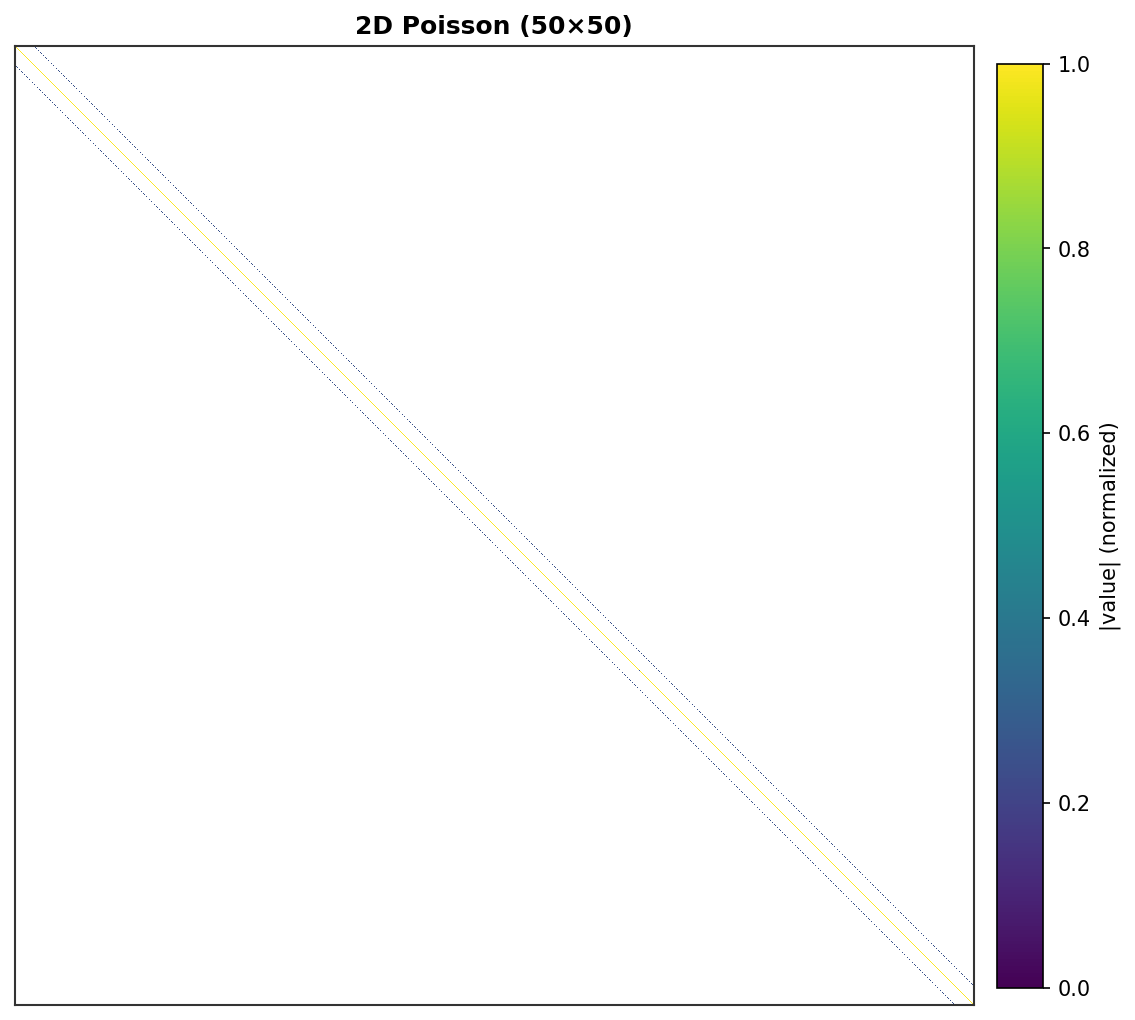
2D Poisson (50×50) - 2,500 DOF,可见带状结构¶ |
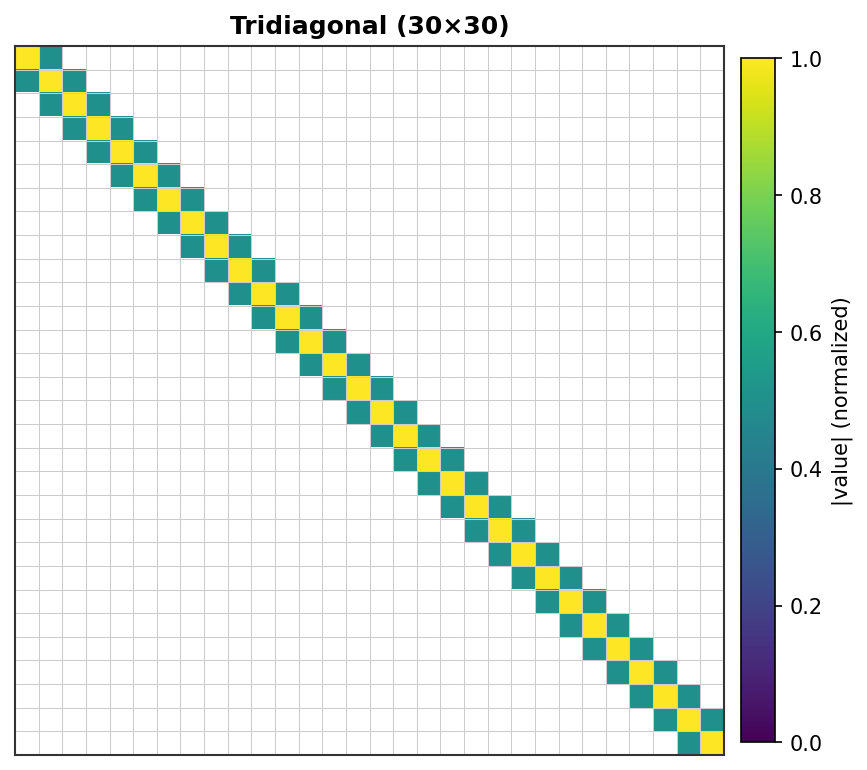
三对角矩阵 (30×30) - 经典1D Poisson模式¶ |
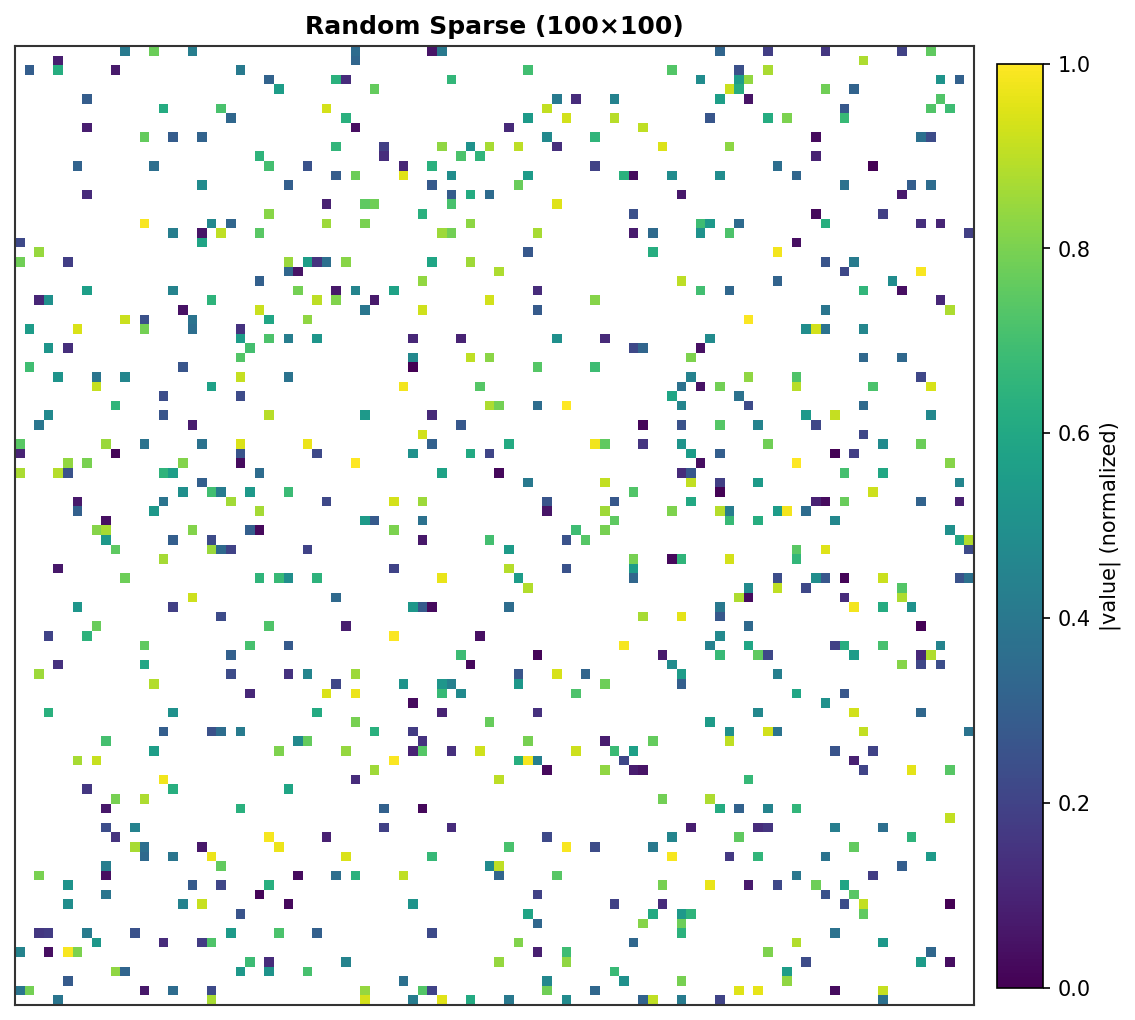
随机稀疏 (100×100) - 800个随机非零元素¶ |
每个非零元素渲染为一个彩色像素,强度与其绝对值成正比。零元素为白色。
I/O 操作¶
Matrix Market 格式¶
以标准 Matrix Market (.mtx) 格式保存和加载稀疏矩阵。
代码:
from torch_sla import SparseTensor, save_matrix_market, load_matrix_market
# 创建稀疏矩阵
A = SparseTensor(val, row, col, (100, 100))
# 保存为 Matrix Market 格式
save_matrix_market(A, "matrix.mtx", comment="我的稀疏矩阵")
# 从 Matrix Market 格式加载
B = load_matrix_market("matrix.mtx", device="cuda")
# 验证
assert torch.allclose(A.to_dense(), B.to_dense())
文件格式 (.mtx):
%%MatrixMarket matrix coordinate real general
% 我的稀疏矩阵
100 100 500
1 1 4.0
1 2 -1.0
...
SafeTensors 格式¶
使用高效的 safetensors 格式保存和加载。
代码:
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, shape)
# 保存
A.save("matrix.safetensors")
# 加载
B = SparseTensor.load("matrix.safetensors", device="cuda")
# 分布式保存(用于多卡)
A.save_distributed("matrix_dist/", num_partitions=4)
基本用法¶
基本稀疏线性求解¶
使用 SparseTensor 求解稀疏线性系统 \(Ax = b\)。
线性系统:
给定稀疏矩阵 \(A \in \mathbb{R}^{n \times n}\) 和右端项 \(b \in \mathbb{R}^n\),求 \(x \in \mathbb{R}^n\) 使得:
求解方法:
直接求解器 (LU, Cholesky):精确解,稀疏情况下 \(O(n^{1.5})\)
迭代求解器 (CG, BiCGStab):近似解,\(O(k \cdot \text{nnz})\),其中 \(k\) 是迭代次数
问题:
这是来自1D Poisson离散化的3×3对称正定(SPD)三对角矩阵。
解:
代码:
import torch
from torch_sla import SparseTensor
# 从稠密矩阵创建稀疏矩阵(小矩阵更易读)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64)
x = A.solve(b)
属性检测¶
检测矩阵属性以优化求解器选择。
对称性: \(A = A^T\)
正定性: 所有特征值 \(\lambda_i > 0\)
对于三对角矩阵::math:`lambda_1 approx 2.59, lambda_2 = 4.0, lambda_3 approx 5.41`(全为正 → SPD)
代码:
from torch_sla import SparseTensor
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
is_sym = A.is_symmetric() # tensor(True)
is_pd = A.is_positive_definite() # tensor(True)
梯度计算¶
通过隐式微分计算稀疏求解的梯度。
隐式微分:
给定 \(x = A^{-1} b\),对于损失函数 \(L(x)\),我们需要 \(\frac{\partial L}{\partial A}\) 和 \(\frac{\partial L}{\partial b}\)。
伴随法:
定义伴随变量 \(\lambda = A^{-T} \frac{\partial L}{\partial x}\),则:
代码:
import torch
from torch_sla import spsolve
val = torch.tensor([4.0, -1.0, -1.0, 4.0, -1.0, -1.0, 4.0],
dtype=torch.float64, requires_grad=True)
row = torch.tensor([0, 0, 1, 1, 1, 2, 2])
col = torch.tensor([0, 1, 0, 1, 2, 1, 2])
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64, requires_grad=True)
x = spsolve(val, row, col, (3, 3), b)
loss = x.sum()
loss.backward()
# val.grad, b.grad 现在包含梯度
指定后端和方法¶
显式选择求解器后端和方法。
可用选项:
后端 |
设备 |
方法 |
|---|---|---|
|
CPU |
|
|
CPU |
|
|
CUDA |
|
|
CUDA |
|
代码:
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, (n, n))
b = torch.randn(n, dtype=torch.float64)
x1 = A.solve(b, backend='scipy', method='superlu') # 直接法
x2 = A.solve(b, backend='scipy', method='cg') # 迭代法(SPD)
x3 = A.solve(b, backend='scipy', method='bicgstab') # 迭代法(一般)
批量求解¶
批量 SparseTensor¶
求解具有相同稀疏模式但不同值的多个系统。
问题: 求解4个缩放矩阵的系统
代码:
import torch
from torch_sla import SparseTensor
val = torch.tensor([4.0, -1.0, -1.0, 4.0, -1.0, -1.0, 4.0], dtype=torch.float64)
row = torch.tensor([0, 0, 1, 1, 1, 2, 2])
col = torch.tensor([0, 1, 0, 1, 2, 1, 2])
batch_size = 4
val_batch = val.unsqueeze(0).expand(batch_size, -1).clone()
for i in range(batch_size):
val_batch[i] = val * (1.0 + 0.1 * i)
A = SparseTensor(val_batch, row, col, (batch_size, 3, 3))
b = torch.randn(batch_size, 3, dtype=torch.float64)
x = A.solve(b) # x.shape: [4, 3]
SparseTensorList¶
处理具有不同稀疏模式的矩阵。
用例: 不同元素数量的有限元网格
代码:
from torch_sla import SparseTensor, SparseTensorList
A1 = SparseTensor(val1, row1, col1, (5, 5))
A2 = SparseTensor(val2, row2, col2, (10, 10))
A3 = SparseTensor(val3, row3, col3, (15, 15))
matrices = SparseTensorList([A1, A2, A3])
b_list = [torch.randn(5), torch.randn(10), torch.randn(15)]
x_list = matrices.solve(b_list)
参见 批量求解示例。
迭代求解器¶
PyTorch CG 求解器¶
对于大规模问题(> 10万 DOF),迭代方法比直接求解器快得多。
共轭梯度(CG)算法:
对于对称正定(SPD)矩阵 \(A\),CG 最小化:
最小值在 \(x^* = A^{-1} b\) 处达到。
收敛性:
CG 在最多 \(n\) 次迭代内收敛(精确算术)。条件数为 \(\kappa = \lambda_{\max}/\lambda_{\min}\) 时:
收敛示例:
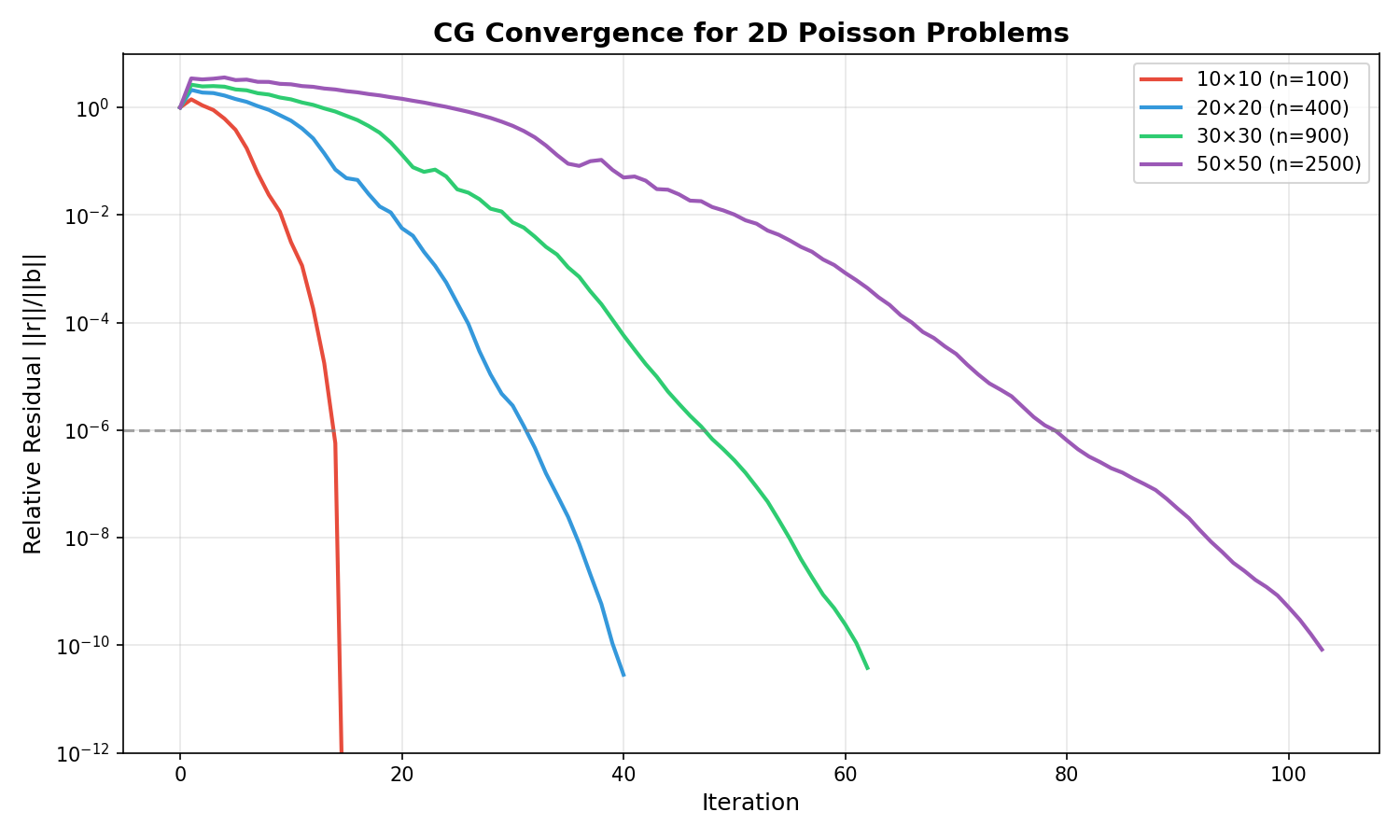
不同规模2D Poisson问题的CG收敛曲线。较大问题由于条件数更差需要更多迭代。¶
性能对比(100万 DOF,NVIDIA H200):
方法 |
时间 |
内存 |
最适用于 |
|---|---|---|---|
|
0.5s ✅ |
~500 MB |
> 10万 DOF,SPD |
|
7.8s |
~300 MB |
< 10万 DOF,高精度 |
代码:
from torch_sla import spsolve
# 对于大型 SPD 系统,使用 PyTorch CG
x = spsolve(val, row, col, shape, b,
backend='pytorch',
method='cg',
preconditioner='jacobi')
分布式求解¶
基本 DSparseTensor¶
使用域分解创建分布式稀疏张量。
域分解: 将16节点网格分成2个域
每个域有 自有节点 和来自邻居的 halo/ghost节点。
代码:
from torch_sla import DSparseTensor
D = DSparseTensor(val, row, col, (16, 16), num_partitions=2)
for i in range(D.num_partitions):
p = D[i]
# p.num_owned, p.num_halo, p.num_local
Halo 交换¶
在相邻分区之间交换ghost节点值。
1D 分解示意图:
分区 0: 自有 [0,1,2,3], Halo [4] ← 来自 P1
分区 1: 自有 [4,5,6,7], Halo [3] ← 来自 P0
交换过程:
之前: P0=[x0,x1,x2,x3,?], P1=[x4,x5,x6,x7,?]
↓ halo_exchange_local()
之后: P0=[x0,x1,x2,x3,x4], P1=[x4,x5,x6,x7,x3]
为什么需要: 对于 \(y_3 = \sum_j A_{3,j} x_j\),节点3需要来自P1的 \(x_4\)。
代码:
from torch_sla import DSparseTensor
D = DSparseTensor(val, row, col, shape, num_partitions=4)
x_list = [torch.randn(D[i].num_local) for i in range(D.num_partitions)]
D.halo_exchange_local(x_list)
高级示例¶
非线性求解与伴随梯度¶
使用伴随法求解非线性方程 \(F(u, \theta) = 0\) 并自动计算梯度。
Newton-Raphson 方法:
从初始猜测 \(u_0\) 开始,迭代:
其中 \(J_F = \frac{\partial F}{\partial u}\) 是Jacobian矩阵。
示例: 非线性扩散 \(Au + u^2 = f\)
import torch
from torch_sla import SparseTensor
# 创建刚度矩阵
A = SparseTensor(val, row, col, (n, n))
# 定义非线性残差: F(u) = Au + u² - f
def residual(u, A, f):
return A @ u + u**2 - f
# 带梯度的参数
f = torch.randn(n, requires_grad=True)
u0 = torch.zeros(n)
# 使用 Newton-Raphson 求解
u = A.nonlinear_solve(residual, u0, f, method='newton')
# 通过伴随法计算梯度(内存高效)
loss = u.sum()
loss.backward()
print(f.grad) # ∂L/∂f
特征值分解¶
计算稀疏矩阵的特征值和特征向量。
特征值问题:
对于矩阵 \(A \in \mathbb{R}^{n \times n}\),求特征值 \(\lambda_i\) 和特征向量 \(v_i\) 使得:
示例输出:
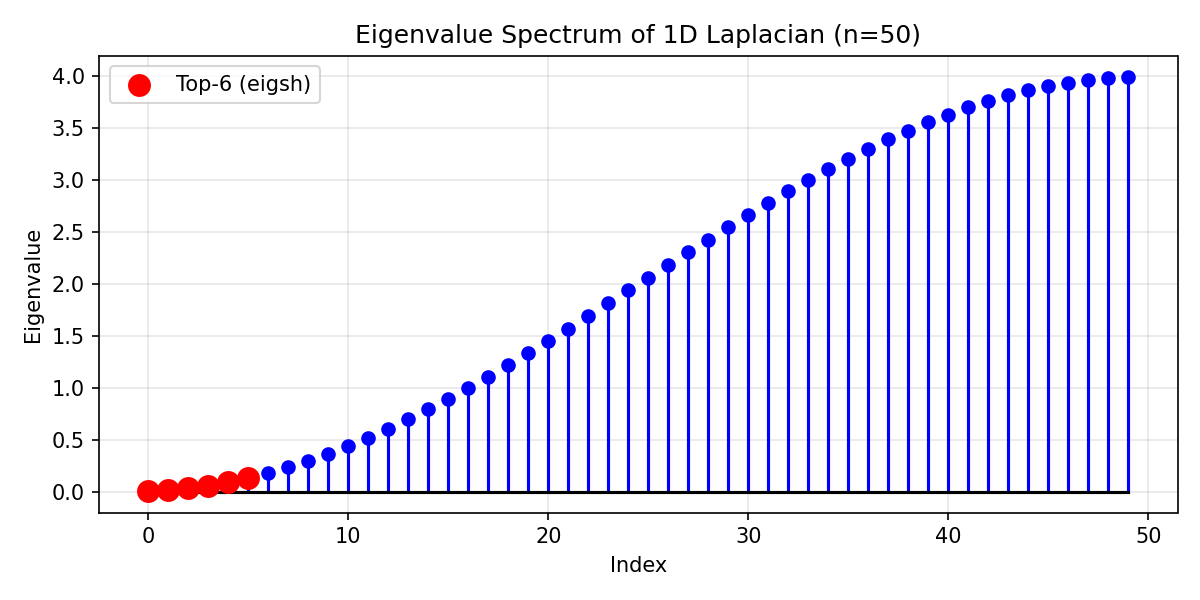
1D Laplacian (n=50) 的特征值谱。红点显示 eigsh() 计算的6个最小特征值。¶
代码:
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, (n, n))
# 最大特征值(ARPACK/LOBPCG)
eigenvalues, eigenvectors = A.eigsh(k=6, which='LM')
# 最小特征值
eigenvalues, eigenvectors = A.eigsh(k=6, which='SM')
# 非对称矩阵
eigenvalues, eigenvectors = A.eigs(k=6)
梯度支持: 特征值分解是可微分的!
val = val.requires_grad_(True)
A = SparseTensor(val, row, col, shape)
eigenvalues, _ = A.eigsh(k=3)
loss = eigenvalues.sum()
loss.backward() # 梯度流向 val
SVD(奇异值分解)¶
计算稀疏矩阵的截断SVD。
SVD 定义:
对于矩阵 \(A \in \mathbb{R}^{m \times n}\),SVD为:
其中:
\(U \in \mathbb{R}^{m \times r}\):左奇异向量
\(\Sigma = \text{diag}(\sigma_1, \ldots, \sigma_r)\):奇异值
\(V \in \mathbb{R}^{n \times r}\):右奇异向量
示例输出:
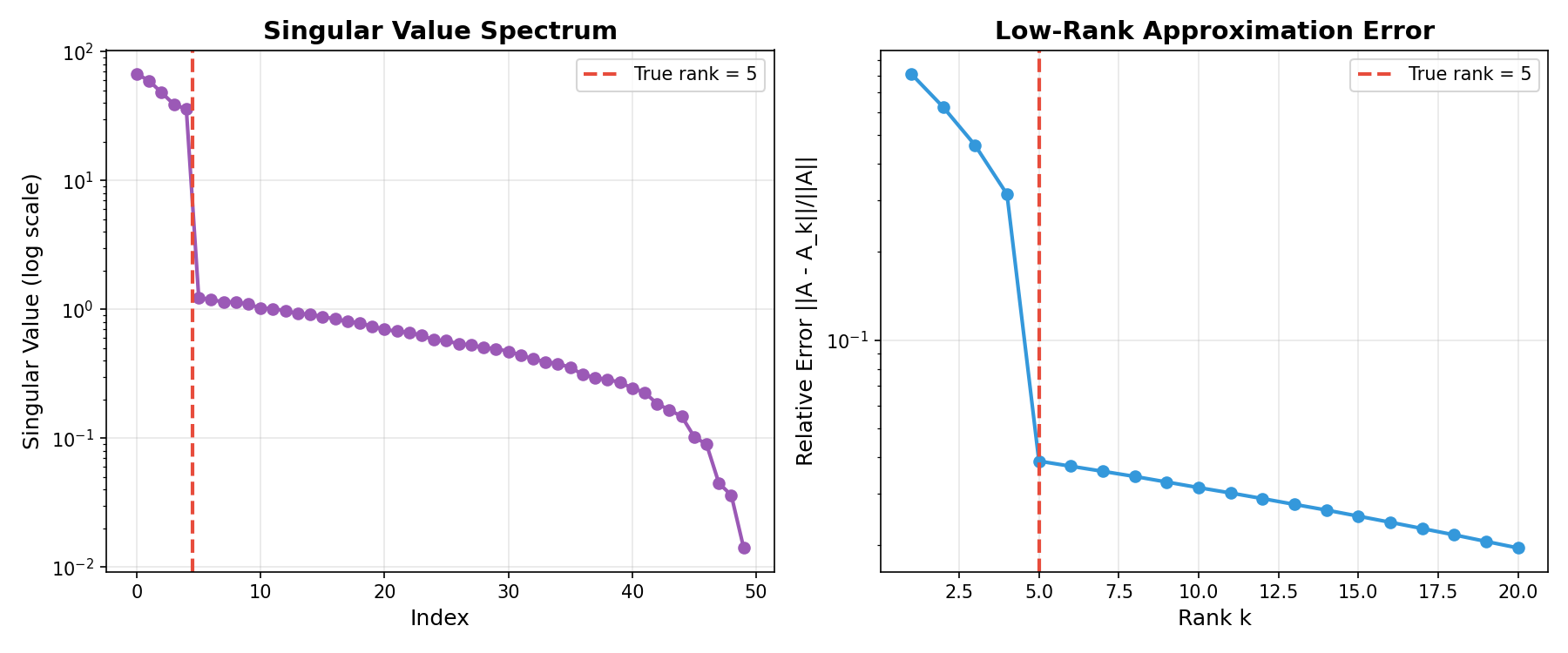
左:奇异值谱显示真实秩后的快速衰减。右:近似误差随秩增加而减少。¶
代码:
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, (m, n))
# 计算前k个奇异值/向量
U, S, Vt = A.svd(k=10)
# 低秩近似
A_approx = U @ torch.diag(S) @ Vt
# 相对近似误差
error = (A.to_dense() - A_approx).norm() / A.norm('fro')
LU分解用于重复求解¶
缓存LU分解以高效地对同一矩阵进行重复求解。
复杂度节省:
对于同一矩阵的 \(k\) 次求解:
无缓存::math:`O(k cdot n^{1.5})`(稀疏直接法)
使用LU缓存:\(O(n^{1.5} + k \cdot n)\) — 最多快 \(\sqrt{n}\) 倍!
用例: 固定刚度矩阵的时间步进
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, shape)
# 分解一次(昂贵)
lu = A.lu()
# 高效地求解多个右端项(便宜)
for t in range(100):
b_t = compute_rhs(t)
x_t = lu.solve(b_t) # 使用缓存的LU快速求解
CUDA 用法¶
移动到 CUDA¶
传输到GPU进行CUDA加速求解。
性能: cuDSS/cuSOLVER 对于大型系统可快10-100倍。
代码:
from torch_sla import SparseTensor
A = SparseTensor(val, row, col, shape)
A_cuda = A.cuda()
x = A_cuda.solve(b.cuda())
CUDA上的后端选择¶
自动选择: cuDSS(首选)→ cuSOLVER(备选)
代码:
x = A_cuda.solve(b_cuda, backend='cudss', method='lu')
x = A_cuda.solve(b_cuda, backend='cudss', method='cholesky') # 对于 SPD
x = A_cuda.solve(b_cuda, backend='cusolver', method='qr')
Jupyter Notebook 示例¶
交互式示例在 examples/ 目录中以Jupyter notebook形式提供:
Notebook |
描述 |
|---|---|
|
基本求解、属性检测、可视化 |
|
批量操作和 SparseTensorList |
|
带梯度支持的行列式计算(CPU 和 CUDA) |
|
稀疏 Laplacian 图神经网络 |
|
带伴随梯度的非线性方程 |
|
Spy图和稀疏可视化 |
|
使用 safetensors 和 Matrix Market 保存/加载 |
|
从 SuiteSparse Collection 加载矩阵 |
|
分布式计算示例(matvec, solve, eigsh) |