基准测试¶
本节展示 torch-sla 在各种问题规模上的性能基准测试结果。
测试环境¶
GPU: NVIDIA H200 (140GB)
CPU: 服务器级 CPU
问题: 2D Poisson 方程 (5点差分格式)
精度: float64
性能对比¶
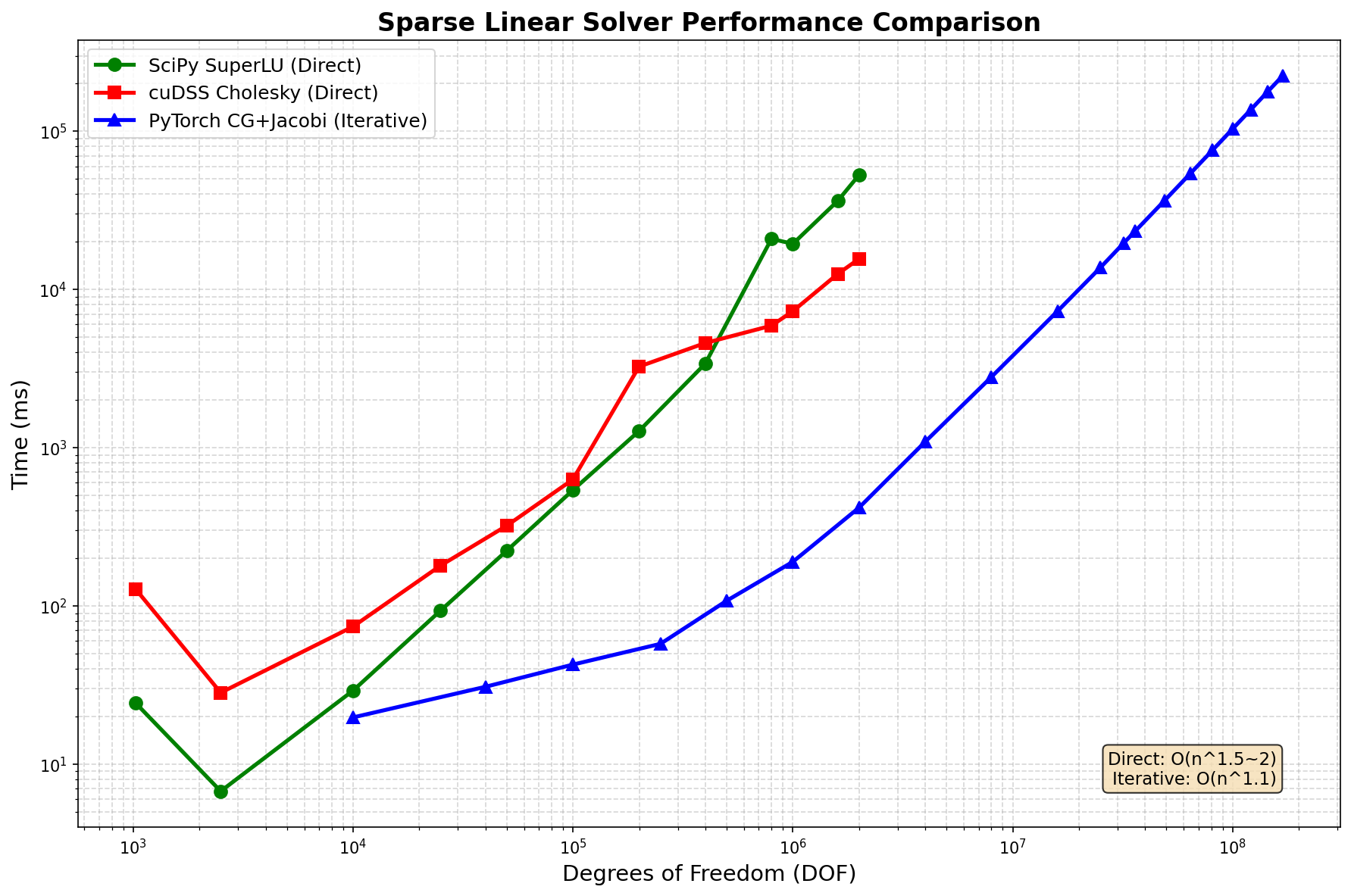
DOF |
SciPy SuperLU |
cuDSS Cholesky |
PyTorch CG+Jacobi |
最优 |
|---|---|---|---|---|
1万 |
24 |
128 |
20 |
PyTorch |
10万 |
29 |
630 |
43 |
SciPy |
100万 |
19,400 |
7,300 |
190 |
PyTorch 100x |
200万 |
52,900 |
15,600 |
418 |
PyTorch 100x |
1600万 |
OOM |
OOM |
7,300 |
PyTorch only |
8100万 |
OOM |
OOM |
75,900 |
PyTorch only |
1.69亿 |
OOM |
OOM |
224,000 |
PyTorch only |
内存使用¶
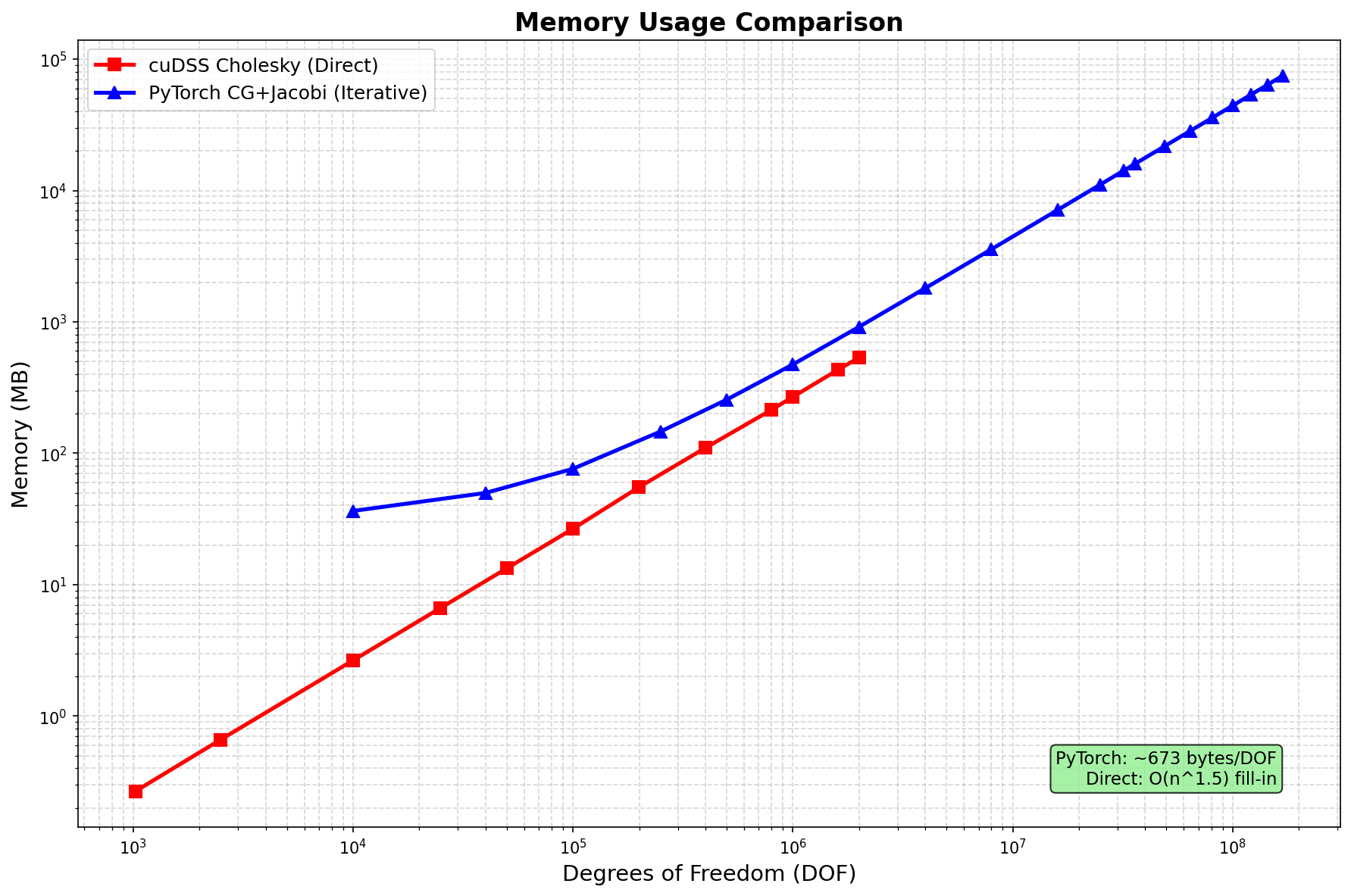
方法 |
内存扩展 |
备注 |
|---|---|---|
SciPy SuperLU |
O(n^1.5) 填充 |
仅 CPU,限于 ~200万 DOF |
cuDSS Cholesky |
O(n^1.5) 填充 |
GPU,限于 ~200万 DOF |
PyTorch CG+Jacobi |
O(n) ~443 字节/DOF |
可扩展至 1.69亿+ DOF |
精度¶
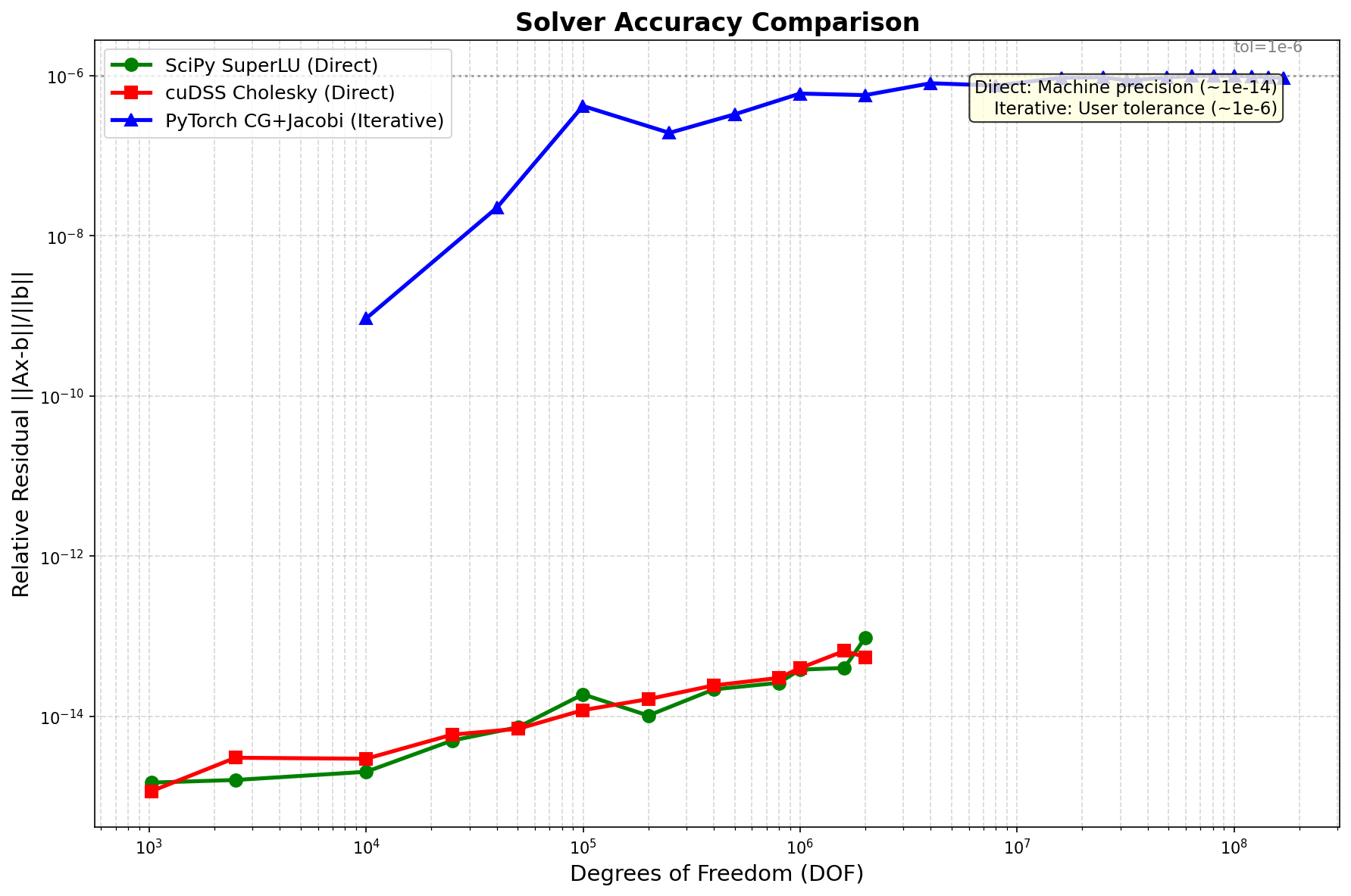
方法类型 |
相对残差 |
备注 |
|---|---|---|
直接法 (scipy, cudss) |
~1e-14 |
机器精度 |
迭代法 (pytorch+cg) |
~1e-6 |
用户可配置容差 |
关键发现¶
迭代求解器可扩展至 1.69亿 DOF,时间复杂度 O(n^1.1)
直接求解器限于 ~200万 DOF,因 O(n^1.5) 内存填充
PyTorch CG+Jacobi 在 200万 DOF 时比直接法快 100 倍
内存高效: 443 字节/DOF (理论最小 144 字节/DOF)
权衡: 直接法达机器精度,迭代法 ~1e-6
分布式求解 (多GPU)¶
3-4x NVIDIA H200 GPU,NCCL 后端:
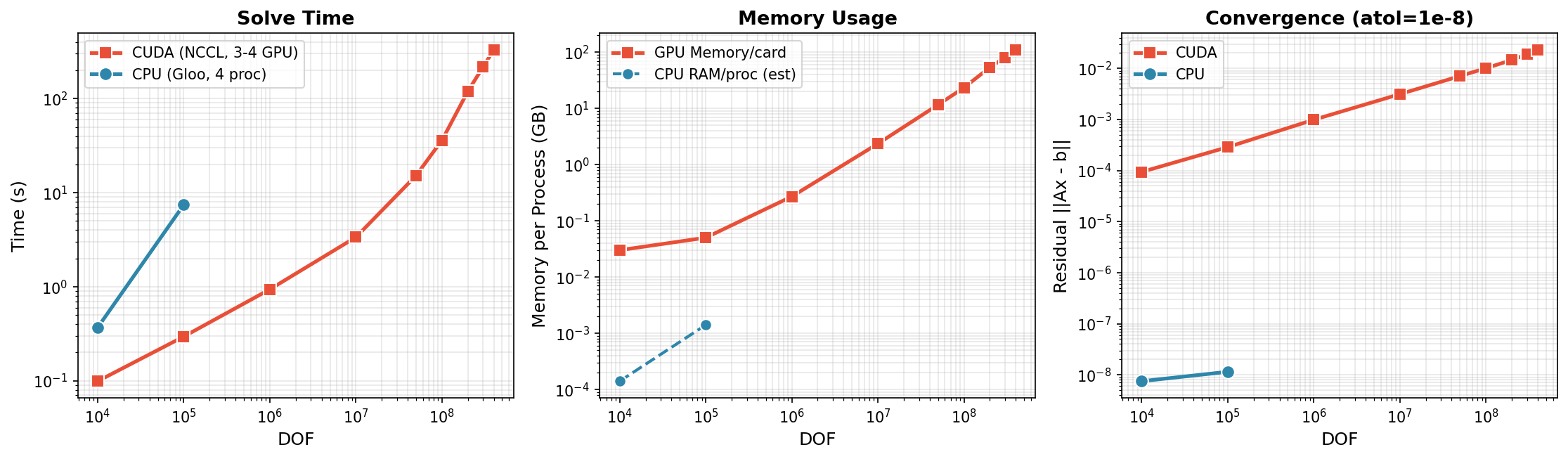
DOF |
时间 |
每GPU内存 |
GPU数 |
|---|---|---|---|
1万 |
0.1s |
0.03 GB |
4 |
10万 |
0.3s |
0.05 GB |
4 |
100万 |
0.9s |
0.27 GB |
4 |
1000万 |
3.4s |
2.35 GB |
4 |
5000万 |
15.2s |
11.6 GB |
4 |
1亿 |
36.1s |
23.3 GB |
4 |
2亿 |
119.8s |
53.7 GB |
3 |
3亿 |
217.4s |
80.5 GB |
3 |
4亿 |
330.9s |
110.3 GB |
3 |
关键发现:
可扩展至 4亿 DOF,使用 3x H200 GPU (110 GB/GPU)
近线性扩展: 1000万→4亿 为 40x DOF,~100x 时间
内存高效: ~275 字节/DOF 每 GPU
5亿 DOF 需要 >140GB/GPU,超出 H200 容量
运行分布式基准测试¶
# 使用 4 GPU 运行分布式求解
torchrun --standalone --nproc_per_node=4 examples/distributed/distributed_solve.py